Hi, in this post I will explain the models used by my windows software AI player. A quick reminder, nothing here is new, there are a lot of papers on the subject with great models. I will share mostly my learning curve.
Some facts:
- The models used by the player work in frequency domain. The STFT is calculated by the player (using the classic lib FFTW) and passed to the model. The model does the separation and passes the result spectrograms back to the player that converts them to time domain.
- The magnitude spectrum data fed to the model has a shape of 1024x192x2. That’s 1024 bins (11 KHz top frequency), by 192 windows, for two channels (L and R). Only magnitude is passed. The phase of the source signal is reused for the stems on reconstruction.
- Used TensorFlow to train and run models. Python and TensorFlow for training. Microsoft C# with ML.net and TensorFlow wrapper (Microsoft.ML.TensorFlow).
Why frequency domain ?
Well, this is an easy one. It’s what seemed logical at first… A year ago, with the ChatGPT boom, I was really curious on what could be done with audio. Found some great models working online like LALAL.AI, and wanted to do something that could do that.
Of course, since I’ve been working with audio and music for a long time, my first idea was: “Feed a magnitude spectrum to a model, and get the spectrum corresponding to the stem”. Spectrograms are easier to read for humans, as we can see frequency components, so I though this would be better for a model too.
I started searching for image models and found Pix2Pix as a TensorFlow tutorial, ready to run, on a notebook. You have to consider that I didn’t know anything of python, less TensorFlow at the time, so I would grab whatever I could get working in no time. I started messing with that, with at least a positive result, vocals where isolated, not perfectly, but much better than I could do manually.
I stuck with the frequency domain because, at least for me, it was easier to get decent results. On the time domain (trying Wave-Unet and a simple Unet) the results were not good. I guess I was doing something wrong, but in the frequency domain decent results are easier to get, or at least, is harder to screw the model.
Currently the best stem separation models are right now hybrid models, but didn’t want to start doing that way before achieving a decent result on the frequency domain.
I tested various windows settings (for the STFT) and stuck with a 4096 window with a 0.75 overlap, that means that a window is taken every 1024 samples. So, for example, if I take 100 windows, I will feed the model 1024x100x2, where 1024 is the number of bins (which I limit to 11 KHz for speed), 100 the number of windows, and 2 the channels (stereo input).
The models
After playing a lot with ideas on CNN (4-6 months probably), I decided to go with an U-net and just start programming the player (in C# .net).
First version (0.1) is a simple u-net (with skip connections). Here’s the diagram.
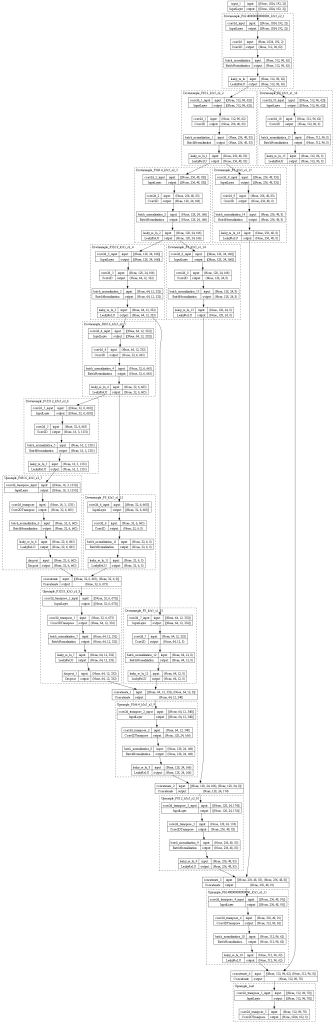
The only difference with a standard u-net is that I reduce the number of filters in the skip connections to speed up things a little.
So, I spent A LOT of time trying simple alternatives to improve the result of a model, like, applying auditory masking rules to the loss function (in theory to have a loss that reflects better the human audition). Splitting the spectrum into bands, so the model would prioritize bands (use more filters) where more important information is present, and of course, messing with the model (like number of layers, etc, etc). Masking didn’t do much, neither bands, they would just change the shape of the sound, the frequency response. But the overall result would be the same which is “the drums bleed into vocals”
The D3 Net model
Looking for frequency domain models for stem separation I found the D3Net by Sony. This is what I consider is the best pure CNN model available. At the same time, it shows the limits of what a convolutional model can produce.
The quality of sound in vocals is amazing, with every detail, and reverb preserved (but the drums bleed into vocals as before). The other instruments are good, but not as good as the vocals. But, IT IS SLOWWWWWW. It is a dense network, so each block is connected to each other in a layer, this will slow down significantly the network.
I’m a guy running a cheap GPU (a RTX 3060), and I can’t wait my whole life to train models. So, I trained just the vocals, and yes… The results were really good, but when running on the player it used a lot of CPU.
One thing though, is that each model has like about one million parameters, that’s really really reaaaally small. Seems that the speed/memory trade off exists in all contexts.
Going back to my stuff, finding and listening to D3Net made me search for alternatives… This was the best I would be able to get from a CNN, but the CPU usage would be huge, not useful for a player that applies the models on realtime.
The Demucs model
The Demucs model is currently one of the best models for stem separation right now. It’s great, and sounds really good on all stems. This was done by the people on Meta.Ai. Also seems to be pretty fast, could work realtime (I just won’t add it to the player because it will feel like cheating). This model is right now available to use in Audacity for windows, if you don’t have python.
So, the Demucs model has three interesting things:
- It’s hybrid, it uses both frequency and time domain information
- It uses a transformer as bottleneck
- Uses big chunks of audio to improve quality (7-12 seconds of audio is passed to the model). The logic here is that the model can use future or past information to help resolve ambiguities in the input.
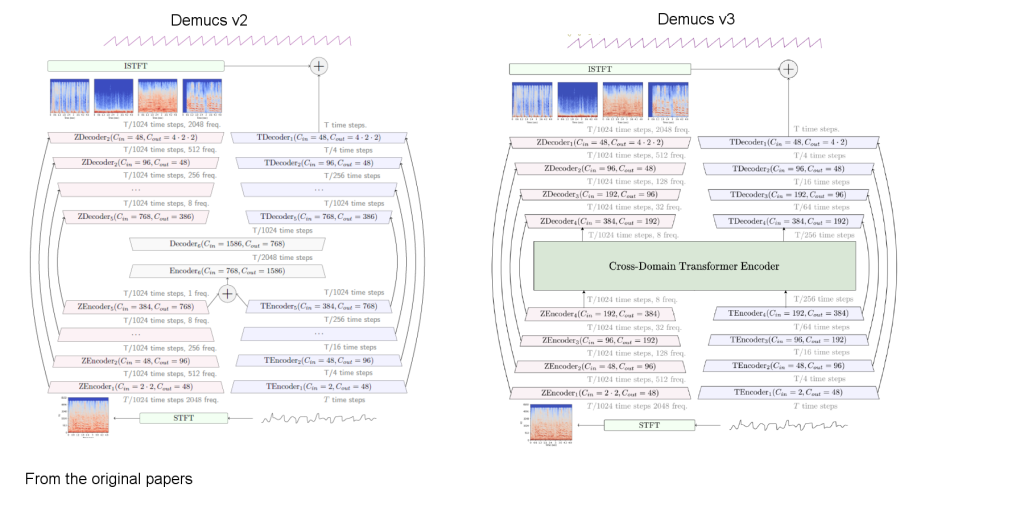
(The difference between Demucs 2 which already has a great separation, using self attention, and Demucs 3 is the bottleneck layer)
Back to my model
So, Demucs uses a transformer, NLP uses transformers, computer vision is now using transformers. Ok, I think, maybe, just maybe, I’m starting to see a pattern here.
Watched various videos explaining transformers, and created a model just to test that. Fortunately tensorflow includes a multihead attention layer (or is it Keras ? ), so half the work was done.
I made a model that will simply reduce each 1024 bins window (remember I feed a tensor of 1024x192x2 to the model) to a single row. No activation on this reduction, just a linear one (a 1024×1 kernel to be applied to the image). I would use the number of filters that would end up being the dimension of the tokens for the transformer.
For example, my model input of (1024x192x2) would end up 1x192xd where d is the number of filters for the convolution, and hence, the dimension of the tokens (384 is a nice number for the dimension). Reshape this into 192xd and here are our 192 tokens.
Position Embedding will be added to this, and then fed to the transformer. Finally the output of the transformer would go through the reverse process to produce the output image (or magnitude spectrum).
It worked ! No activations were used outside the transformer, so it was the transformer doing the separation. Also, it achieved something I couldn’t get before, the drums bleeding was reduced almost entirely.
I wanted to do the obvious and put a transformer in the bottleneck of the UNET. But training was a lot slower when doing that, and I hate to wait 5 hours to know if a model could work. So…
The next step, was to keep the linear activations for the transformer, add a small parallel u-net, and mix their outputs. This would look like this:
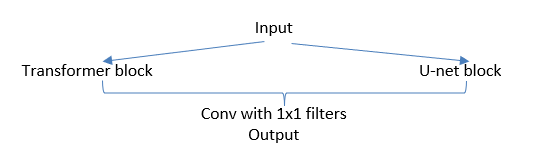
Why ? The output of the transformer alone on the previous experiment, had a real good isolation of the source (vocals and drums), but it missed some details (reverb, or some high frequency content) that in the CNN models was present. Mixing both brought some of those details back.
Another implemented idea was to run both attention layers (one for drums, other for vocals) in parallel, and do cross attention (feed information from drums to vocals and vice versa) in one of the layers. The aim is to reduce the bleeding between these stems which are most common. This worked correctly and reduced the bleeding.
Finally, trained another model for bass, using again a transformer (or self attention layer), but with less parameters, and smaller token dimension. Bass information is not much starting at 500 Hz, so this can be exploited.
Last but not least, the “other” stem. Which contains all the instruments that are not vocals/drums/bass. If the separation is good and the phase is correct, this can be achieved by just subtracting the separated stems from the source waveform. Because the player uses the source phase to reconstruct the signal, it is better to calculate the other stem in the frequency domain too. This is done with a small Unet (again) that receives all the separated stems plus the input, and predicts the rest.
Here’s the diagram of the latest model.
Conclusion
I managed to get a much better separation using transformers. Transformers require more training data and epochs. CNN on the other hand, reach their optimal point a lot sooner, with less training data.
If you want to compare these, you can download the player version 0.1 and 0.1b, open both and do an A/B test on the same track.
Also, here’s a zip file with the stems produced by, the Unet from the first version, D3 net, and the model from the second version. BEWARE: 80s rock music, I love this, most people don’t.
What’s next ? The plan is to start messing with hybrid models… While keeping the model fast.
Links
https://github.com/facebookresearch/demucs